Korpus Online analyzuje jazyk na českém internetu
Ústav Českého národního korpusu Filozofické fakulty UK zprovoznil monitorovací korpus Online, který se snaží mapovat dynamický obsah českého internetu.
Zdroj: MediaGuru.cz
Ústav Českého národního korpusu Filozofické fakulty UK zprovoznil monitorovací korpus Online, který se snaží mapovat dynamický obsah českého internetu, tj. internetovou žurnalistiku. Zachycuje obsah na internetových serverech, v internetových diskusích, na sociálních sítích, a to od roku 2017 do současnosti. Data poskytuje společnost Dataweps.
Korpus Online (velké písmeno ve slově online vyjadřuje název korpusu a jeho zaměření, i ostatní korpusy ČNK jsou dostupné online) přináší uživatelům možnost jazykové analýzy českých online médií. Korpus Online je pravidelně aktualizován a jeho obsah se neustále mění. Aktualizace probíhá každý den cca v 9:00, aktualizace archivu probíhá vždy první den v měsíci.
Korpus je přístupný přes webové rozhraní, vyhledávat je v něm možné zdarma. Je možné zjistit, jak často se konkrétní výrazy v online médiích objevují, v jakých souvislostech (kolokvia) či jaká jsou podobná slova, která se k danému výrazu vztahují.
V grafu níže je např. zachycena preference formulace „zemřít na covid/koronavirus“ vs. „zemřít s covidem/koronavirem“ v bulvárních (horní část grafu) a mainstreamových (dolní část grafu) online médiích. První vyjadřuje explicitně kauzalitu, zatímco druhá formulace spíš koincidenci. Graf naznačuje, že bulvár přešel na variantu „s“ později, zato se ho drží teď důsledněji.
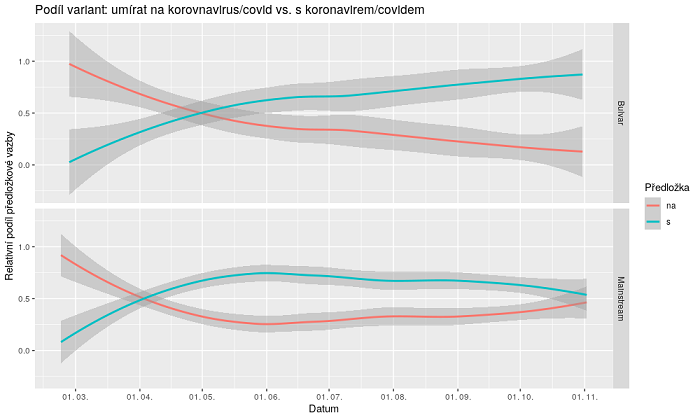
Podíl variant: umírat na koronavirus vs. s koronavirem v bulvárních a v mainstremových online médiích, zdroj: Ústav Českého národního korpusu FF UK
V současnosti (s platností k 11.11. 2020) má Online 6,6 mld. slov, každý den se ale jeho objem zvyšuje o cca 4,5 mil. slov. Korpus monitoruje zhruba 250 různých portálů denně (od hlavního proudu zpravodajských webů přes názorové, analytické weby nebo antisystémové stránky), celkově asi 6000 různých webů denně. Počet různých slov (lemmat) je v denní dávce zhruba 140–150 tisíc.
Bližší informace o korpusu Online poskytl Václav Cvrček, zástupce ředitele Ústavu Českého národního korpusu. Poprvé projekt představil na letošní konferenci New Media Inspiration, která se uskutečnila v březnu.

Václav Cvrček na konferenci New Media Inspiration 2020, zdroj: Internet Info
Otázky pro Václava Cvrčka
Co lze z korpusu Online zjistit a k čemu slouží?
Především je to odraz české internetové žurnalistiky a aktuální celospolečenské agendy. Sekundárně je to nástroj pro studium jazykového vývoje „v přímém přenosu“. Potenciál těchto dat teprve odhalujeme – kromě toho, že můžeme zjistit, o čem se kde psalo (či naopak nepsalo), lze pozorovat, jakým způsobem média o událostech referovala (do jakého rámce události zasazovala) a jaké byly navazovány asociační vztahy mezi tématy. To vše je klíčové pro pochopení probíhajících společenských procesů nebo „celospolečenské diskuse“.
V zásadě si analytik vystačí pouze se zjišťováním frekvencí (četností) slov a jevů a z toho lze vše podstatné odvodit. Na to je třeba ale nejprve taková data mít, a pokud je máte navíc každodenně aktualizovaná, je to výzkumníkův sen.
Co konkrétně vyjadřují k vyhledávaným slovům kolokace a slova podobná?
Musíme začít tím, že slova nemají význam sama o sobě, ale získávají ho až v kontextu. To, že slovem „pes“ rozumíme čtyřnohé chlupaté zvíře, které štěká, je dáno tím, že se vyskytuje mj. v okolí slov „chlupatý“, „štěkat“ apod. Nejinak tomu je i s ostatními jednotkami jazyka, včetně vlastních jmen. To, jak je vnímán Miloš Zeman nebo Andrej Babiš, je přirozeně dáno tím, do jakých kontextů se jejich jména dostávají nebo též, s jakými tématy jsou spojováni. Tenhle fenomén podchycují právě kolokace (dříve ustálená spojení), které vyjadřují tendenci k ustálenému souvýskytu. Takovou silnou kolokací může být třeba cestovní ruch, hlavní nádraží, ale také třeba sarajevský atentát, pražská kavárna nebo tradiční politici. Tyto kolokace do značné míry předurčují způsoby vnímání určitých pojmů, a kdo je umí do debaty prosadit, do značené míry ji ovládá ve svůj prospěch.
Kontextové zapojení slova využívají i techniky identifikace podobných slov, protože pokud je význam určován tím, s čím se slovo spojuje, je jasné, že slova vstupující do podobných kontextů mají i podobný význam.
Lze na základě vyhledávaných slov v korpusu zpracovat jazykovou analýzu online médií, nebo je pro takový účel potřeba ještě dalších nástrojů?
Záleží na tom, co vás zajímá. V zásadě je v korpusu vše, co k tomu potřebujete – obsah, metadata (datum, zdroj, autor apod.). Navíc korpus (tj. data) je přístupný na portále www.korpus.cz přes rozhraní, které je vytvářeno s cílem umožnit analýzu rozsáhlého textového materiálu, tj. třídit, zjišťovat frekvence, filtrovat apod. Problém je spíš v tom, že dat je tolik (každý den přibývá zhruba 4,5 mil. slov), že je třeba umět se v tom zorientovat, aby se člověk v té záplavě neutopil.
Vedle toho existují metody, které umožňují identifikovat prominentní jednotky v textech a nacházet vztahy mezi nimi. Na jejich zpřístupnění pro uživatele bez potřebného programátorského zázemí ale ještě pracujeme.
Kdo může online korpus využívat?
Naše korpusy jsou zdarma přístupné všem uživatelům, kteří se zaregistrují. Jako výzkumná infrastruktura jsme placeni státem za poskytování této služby. Vedle toho jsme schopni realizovat zakázkový výzkum na zpracování určitého tématu nebo dat.
Jaké zdroje jsou pro účely korpusu monitorovány a na jakém základě monitoring pracuje?
Získáváme data od společnosti Dataweps, která dělá svůj monitoring internetu a data nám zdarma poskytuje. Výběr webů je tedy principiálně na nich a my do toho nemůžeme zasahovat. U nás se data jednak čistí a jednak zpracovávají – je jim přidávána anotace (zejm. typ zdroje podle klasifikace našeho fakultního kolegy J. Šlerky publikované na http://www.mapamedii.cz) a dále pak jsou opatřena lingvistickou analýzou, které říkáme lemmatizace a morfologické tagování, aby v korpusu bylo možné hledat slova ve všech tvarech a podle gramatických kategorií. To vše je hotové v průběhu noci a rána tak, aby nový korpus byl k dispozici v 9.00 s daty referujícími o včerejší mediální realitě.
Pokud jde o rozsah zdrojů, korpus obsahuje všechny velké a doménově nespecifické mediální zdroje od mainstreamu (jako jsou novinky.cz, idnes.cz, aktualne.cz), přes analyticko-investigativní a názorové weby (např. hlidacipes.cz, neovlivni.cz, echo24.cz, blisty.cz, vasevec.cz) až po bulvár (blesk.cz, expres.cz apod.) a anti-systémové weby a segment, kterému říkáme politický bulvár (parlamentnilisty.cz, sputniknews.cz, nwoo.org, eportal.cz apod.). Právě ten poslední segment je pro nás výzkumně extrémně zajímavý, protože umožňuje poprvé empirický výzkum současných dezinformačních kampaní a různých mediálních manipulací.
Lze ve vyhledávání nastavovat konkrétní zdroje, nebo výsledky se vždy vztahují k online médiím jako celku?
Metadata umožňují filtrování dat na různých úrovních, takže lze hledat pouze v mainstreamových médiích, nebo jenom v rámci jednoho portálu a v některých případech máme informace i o tom, z jaké tematické části portálu článek pochází (sport, kultura, domácí). Záleží ale hodně na vnitřní struktuře webu.
-mav-
Tagy

